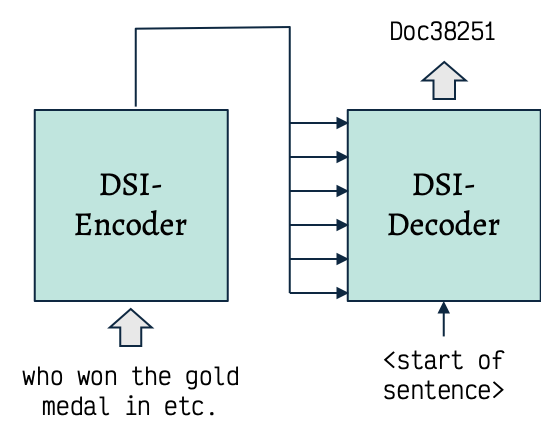
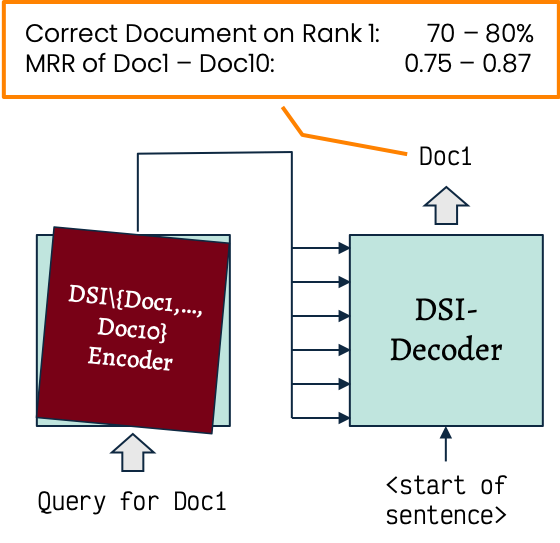
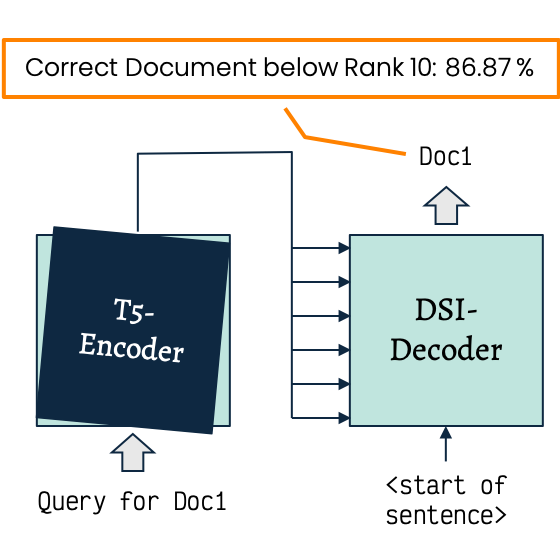
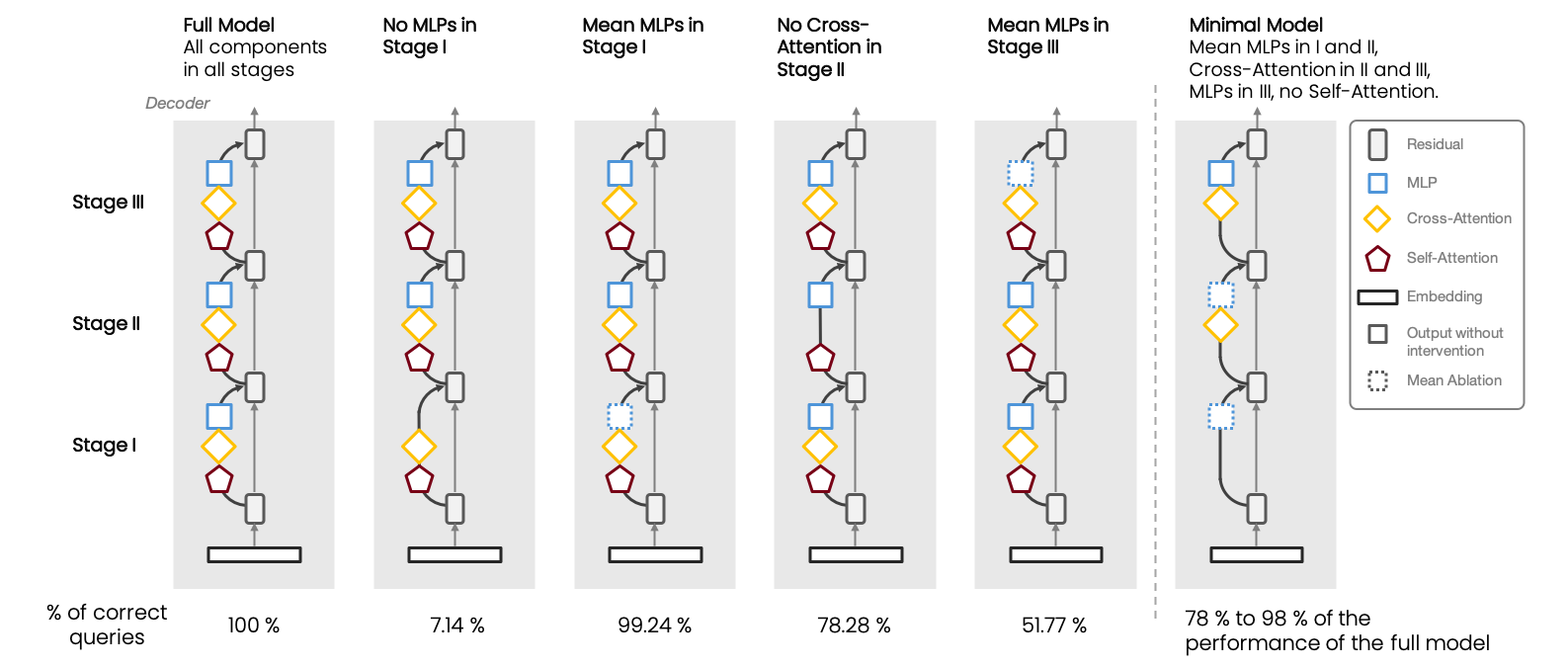
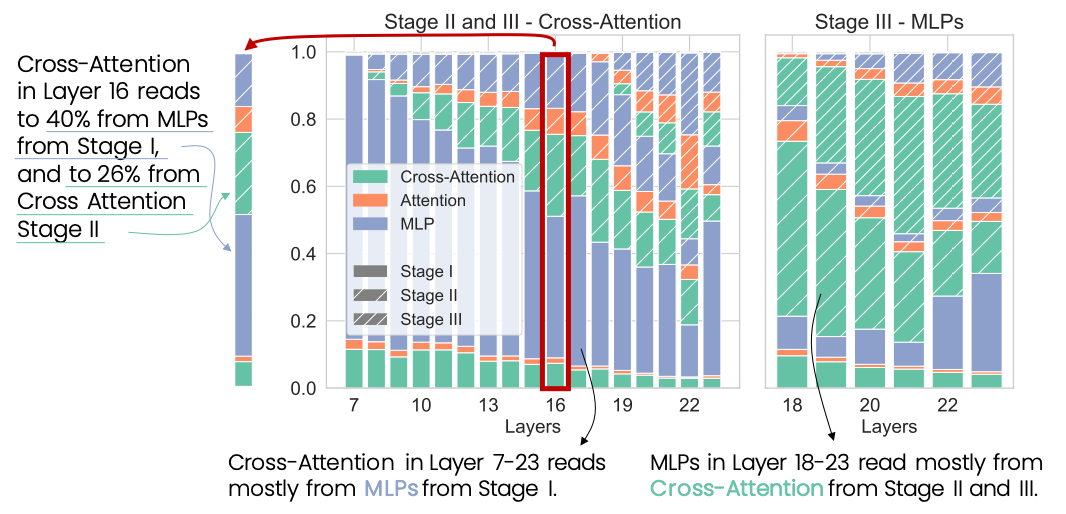
Walkthrough the Retrieval Process
Encoder.
- Embeds the query
- Not required to encode information on the documents directly as it can be replaced by an encoder that does not contain document specific information
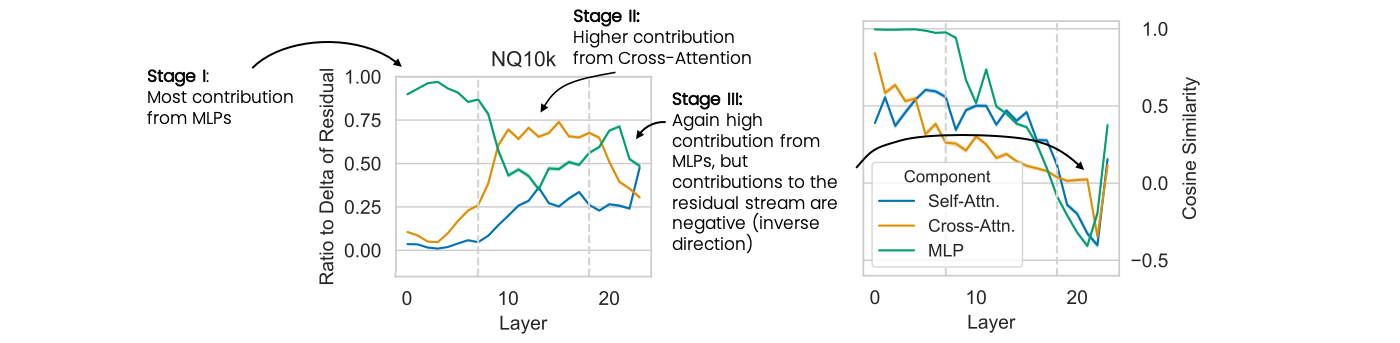
- "Prepares" the residual stream for subsequent stages.
- MLP components move document id tokens to lower ranks and non-document id tokens to higher ranks.
- Does not contain query specific information.
- Cross-attention moves information from the encoder to the decoder.
- Cross-attention heads output information in form of word tokens that resemble a form of query expansion.
- Output of cross-attention is used to activate neurons in the last stage.
- Neurons in MLPs are activated based on the output of the previous stage, promoting document identifiers.
- Cross-attention continues to output query information to the residual stream.
- Last layer: only MLPs are required, they remove all non-document id tokens to high ranks, such that only document id tokens are predicted by the model.
- In this stage, query and documents interact for the first time.
- DSI setup, atomic document identifiers, T5-large,
- Datasets: Natural Questions, TriviaQA, sizes: 10k - 220k documents.