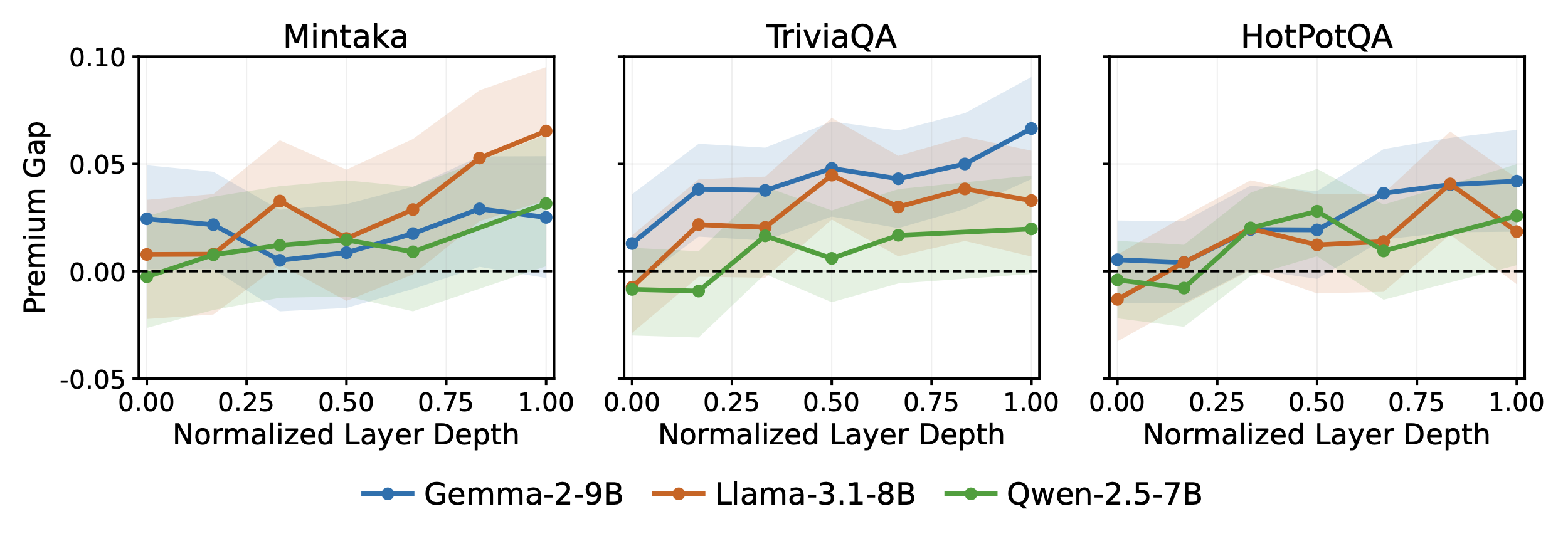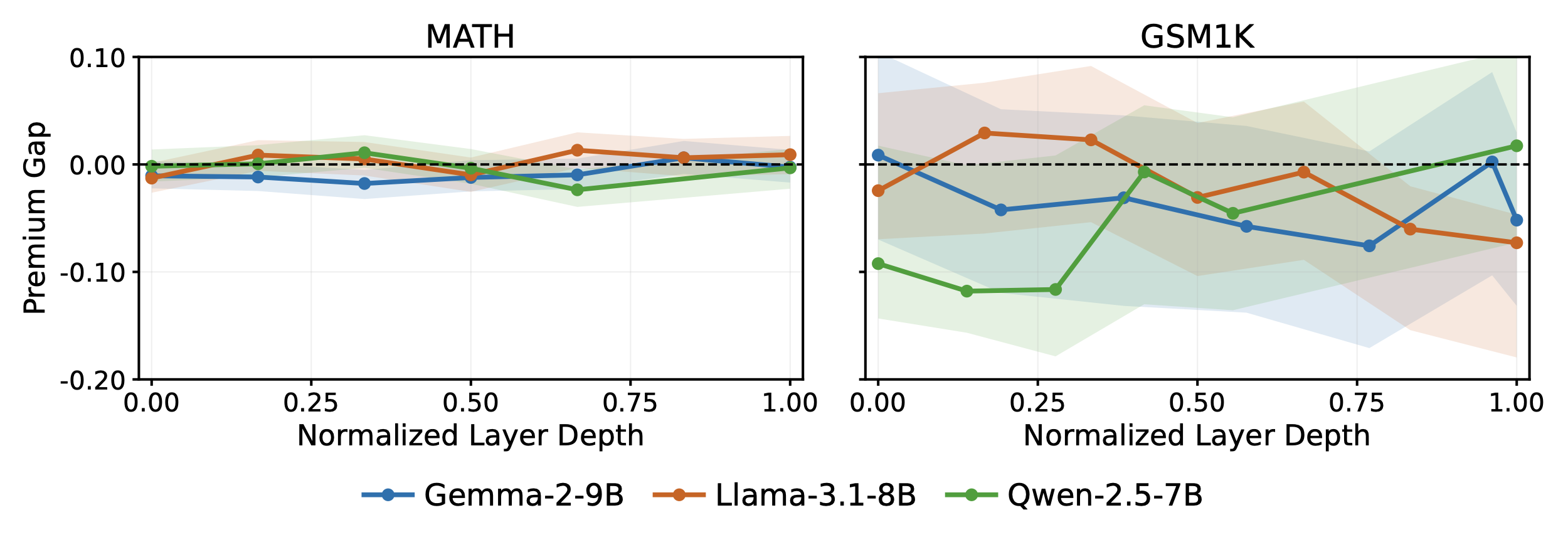
The premium gap is near zero or slightly negative in early layers—which primarily encode surface-level and syntactic features—and grows progressively toward deeper layers. The gap becomes reliably positive from approximately layer 10–15 onward (normalized depth ~0.25–0.40), consistent with the view that the privileged signal reflects idiosyncratic memory retrieval states that build up through the forward pass.
Method Overview
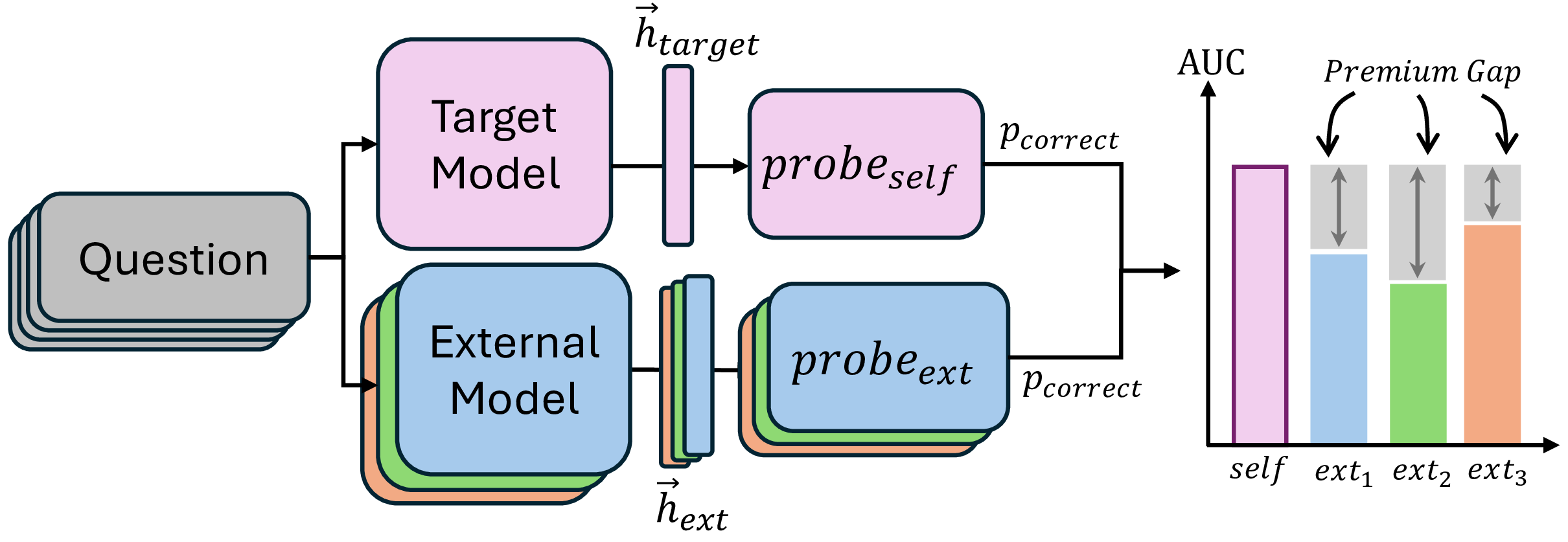
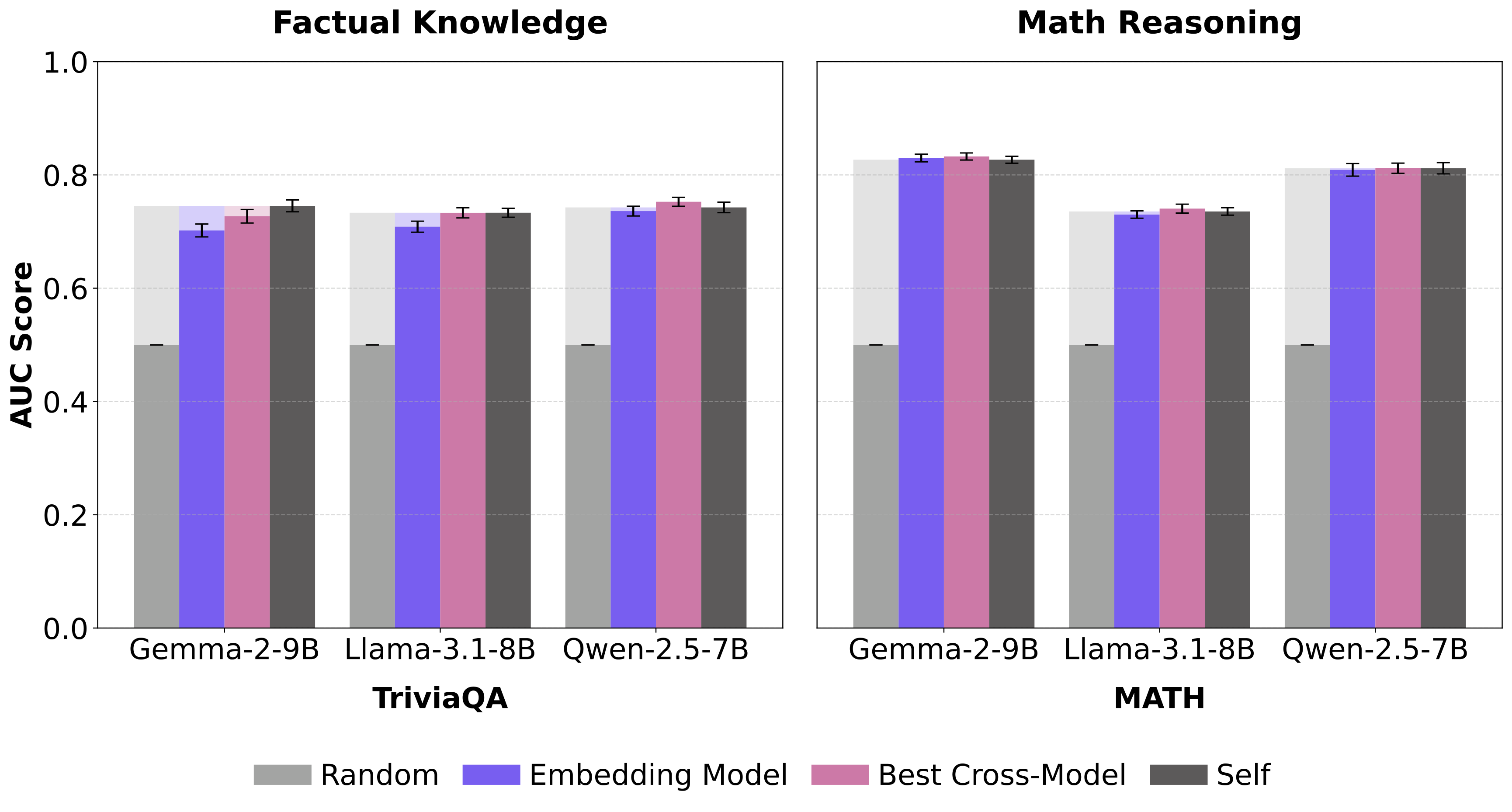
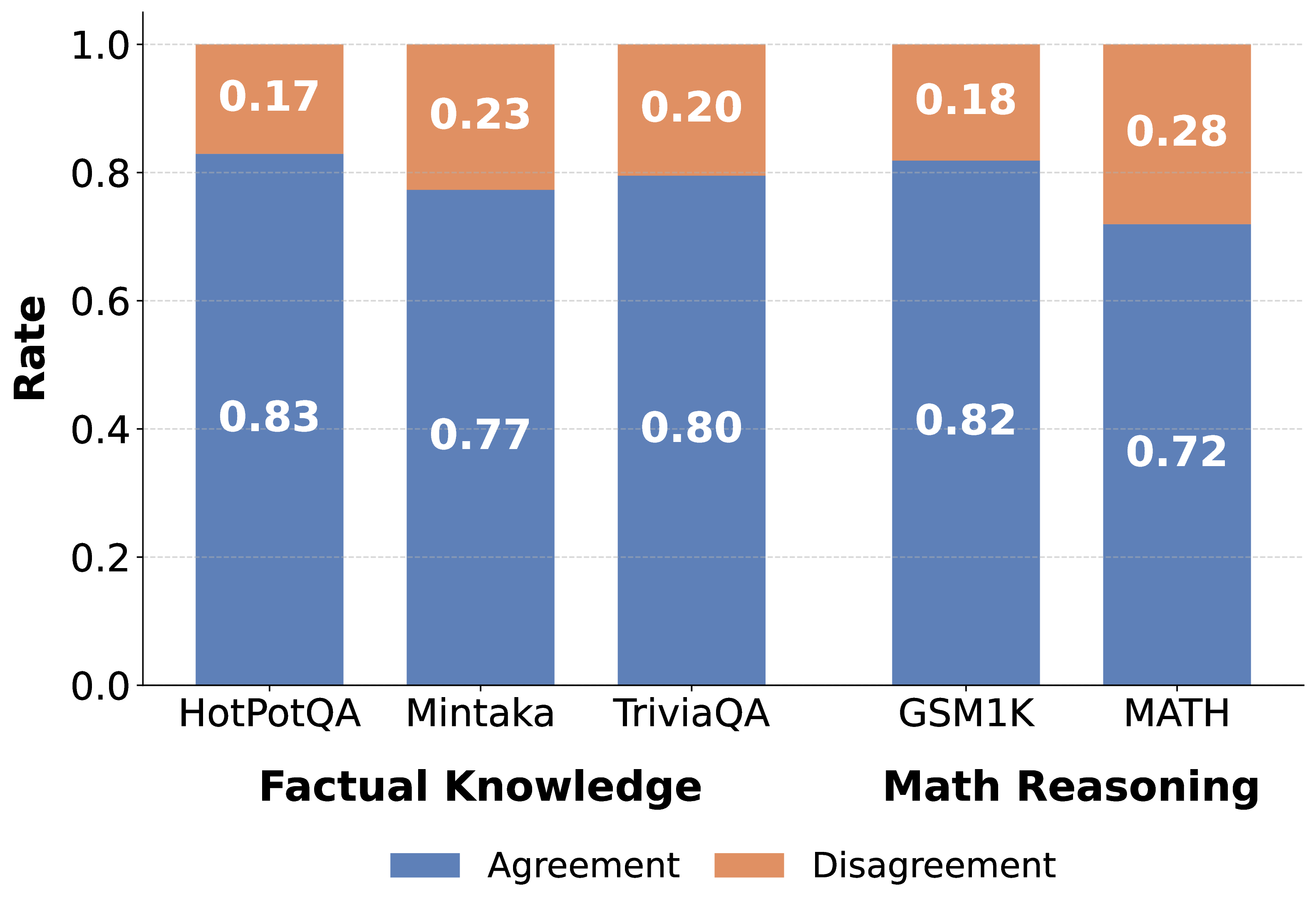
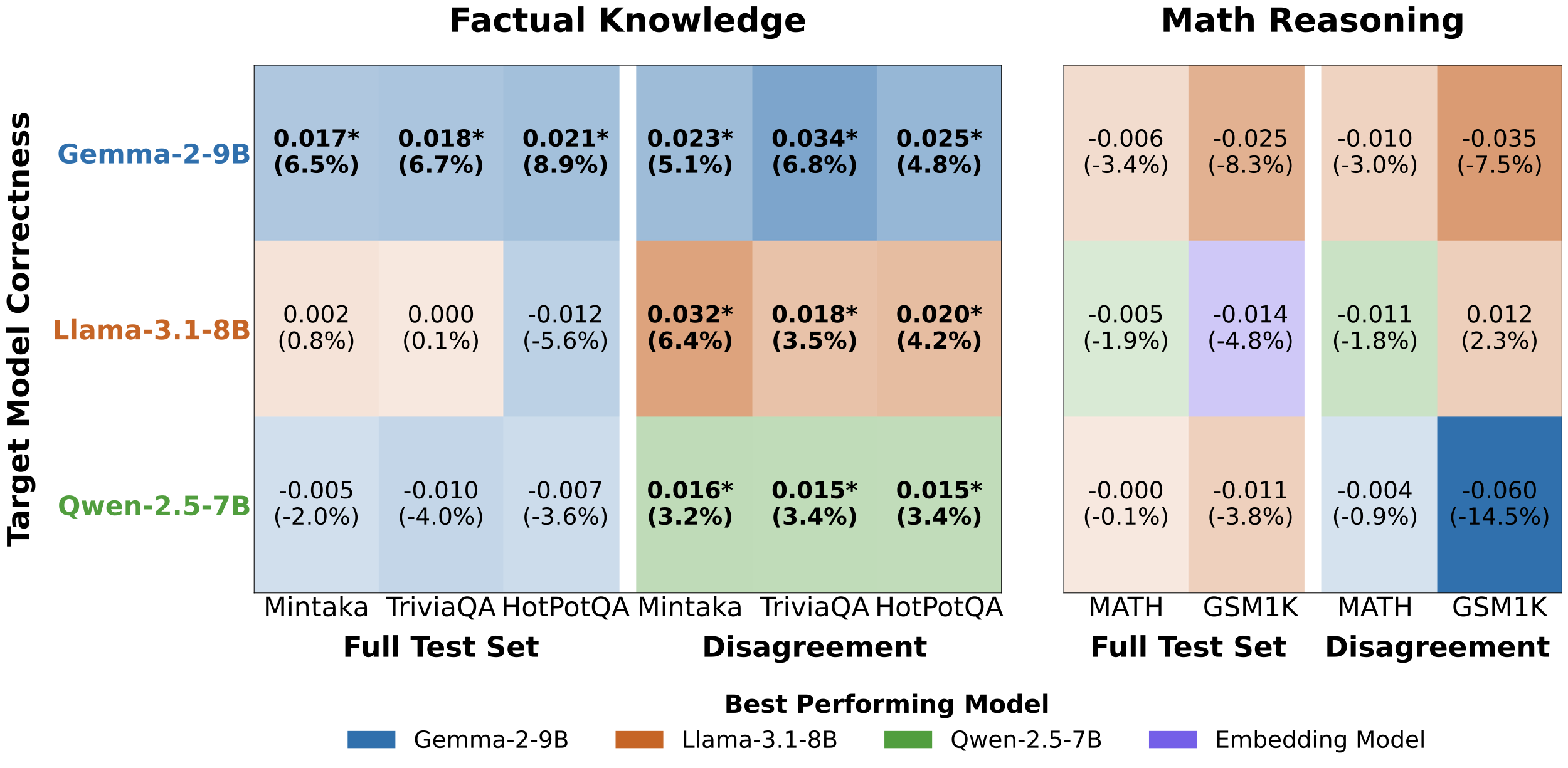
We train correctness probes on a model's own hidden states (self-probe) and on external models' representations (external-probe), then measure the Premium Gap: the performance advantage of self over external probes. We evaluate across three decoder model families (Gemma-2-9B, Llama-3.1-8B, Qwen-2.5-7B), an embedding model (Qwen3-Embedding-8B), and five datasets spanning factual knowledge and mathematical reasoning. We additionally evaluate Qwen-3-32B for scalability analysis.